オライリーから「仕事ではじめる機械学習」が出版されます
技術書典2で好評だった技術書供養寺の薄い本が、この度技術書典3に合わせて商業誌になります!今回も Takashi Nishibayashiさんと ところてんさんとの共著になります。と言っても、基本電子版のみなので技術書典会場では購入できませんし、手にとって見ていただくことが出来ませんのでお気をつけください。なお、自社イベントであるCloudera World Tokyo 2017でプリント・オン・デマンドで物理本を少部数限定で販売する予定です。
【追記】Ebookはこちらから買えます
【/追記】
【追記2】電子版大好評に付き2018年1月16日に物理版も出ました。Amazonさんで売り切れている場合は、お近くの本屋さんにお問い合わせください。

 amazon.co.jp
amazon.co.jp【/追記】

どういう本なの?
まえがきのスクリーンショットを貼りましたが、この本は多くの機械学習の本とは異なり、機械学習の実務で使えるようになるために知りたい、機械学習を含めたシステムのアーキテクチャや機械学習プロジェクトの進め方、効果検証をどうするのかということをまとめました。
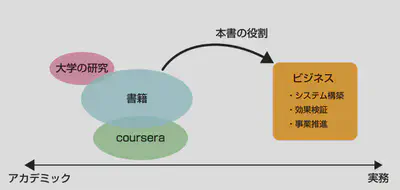
既に多く刊行されているTensorFlowやChainerでディープラーニングをしてみようというものでもなければ、機械学習の理論をわかりやすく解説するといった類のものでもありません。ゼロから作るDeep LearningやCourseraのMachine Learningで学んだけど、実際の仕事に活かすにはどうしたら良いだろう?という疑問に答えているつもりです。また、大学の講義などで機械学習は学んだけど、実際仕事で機械学習のプロジェクトを進めるときはどうすればいいんだろう?という人にも得るものがあると思います。もちろん、敢えて数学の基礎には触れないなど、全てのことを網羅的に書けているわけではありませんが、僕やhagino3000さん、tokorotenさんたちの「業務をする上で身についた当たり前」をdumpした本になります。
hagino3000さんのA/Bテストの話はp値だけでなく検定力の話も含まれております、どういう罠があるかという気をつけるポイントも触れられています。
tokorotenさんのキックスターターの分析は、機械学習をする前の探索的分析とレポーティングの例としてとても面白いです。特に彼独特の語り口で、思考を追いかけるような気持ちで楽しめます。
【追記】
tomo_makesさんにわかりやすい図解をしていただきました。ありがとうございます!【/追記】
薄い本との差分は?
技術書典2で ”Big Mouth Data 2017 Spring” を購入いただいた皆様ありがとうございます。そんな皆様にも、新たに書き下ろしの章が増え、強力なレビューアー陣によるマサカリを反映した読みやすい文章などもう一度おすすめできる内容になったかと思います。
マサカリを投げきった人の感想
以下のような差分があります。
- hagino3000さんによる、統計的検定と効果検証、A/Bテストの章を追加
- tokorotenさんによるマーケティング施策への機械学習としてUplift Modelingの章の追加
- chezouより機械学習の評価の章の追加
- 瀧澤さんによる日本語の大幅なimprove
- 美しいカラー図表
結局、ページ数としてはPDFで200ページ近くという思っていたより大きいボリュームになり、読み応えたっぷりになりました。
どこで買えるの?
オライリー・ジャパンのEbook Storeで10/22(日)買えるようになります。物理本については、11/7(火)のCloudera World Tokyoにお越しになっていただければ会場限定でPODのものが買えます。(サイン会も予定しています)
なお、同日販売の知人の書籍としては Yoshiki Shibukawaさんの「Goならわかるシステムプログラミング」とtk0miyaさんの「Sphinxをはじめよう」が出ます。とくにお二人には同人誌のときにSphinx方面でのサポートを絶賛していただきました。よければ合わせて読んでみてください。
Shibu’s Diary: ASCII.jpの連載「Goならわかるシステムプログラミング」がパワーアップして書籍化されます
_My blog about Software Development (Python, Sphinx, JavaScript, etc)_blog.shibu.jp
目次
最後に目次を貼っておきます。
第I部
1章 機械学習プロジェクトのはじめ方
- 1.1 機械学習はどのように使われるのか
- 1.2 機械学習プロジェクトの流れ
— 1.2.1 問題を定式化する
— 1.2.2 機械学習をしなくて良い方法を考える
— 1.2.3 システム設計を考える
— 1.2.4 アルゴリズムを選定する
— 1.2.5 特徴量、教師データとログの設計をする
— 1.2.6 前処理をする
— 1.2.7 学習・パラメータチューニング
— 1.2.8 システムに組み込む
- 1.3 実システムにおける機械学習の問題点への対処方法
— 1.3.1 人手でゴールドスタンダードを用意して、予測性能のモニタリングをする
— 1.3.2 予測モデルをモジュール化をしてアルゴリズムのA/Bテストができるようにする
— 1.3.3 モデルのバージョン管理をして、いつでも切り戻し可能にする
— 1.3.4 データ処理のパイプラインごと保存する
— 1.3.5 開発/本番環境の言語/フレームワークは揃える
- 1.4 機械学習を含めたシステムを成功させるには
- 1.5 この章のまとめ
2章 機械学習で何ができる?
- 2.1 どのアルゴリズムを選ぶべきか?
- 2.2 分類
— 2.2.1 パーセプトロン
— 2.2.2 ロジスティック回帰
— 2.2.3 SVM
— 2.2.4 ニューラルネットワーク
— 2.2.5 k-NN
— 2.2.6 決定木、ランダムフォレスト、GBDT
- 2.3 回帰
— 2.3.1 線形回帰の仕組み
- 2.4 クラスタリング・次元削減
— 2.4.1 クラスタリング
— 2.4.2 次元削減
- 2.5 その他
— 2.5.1 推薦
— 2.5.2 異常検知
— 2.5.3 頻出パターンマイニング
— 2.5.4 強化学習
- 2.6 この章のまとめ
3章 学習結果を評価しよう
- 3.1 分類の評価
— 3.1.1 正解率を使えば良いのか?
— 3.1.2 データ数の偏りを考慮する適合率と再現率
— 3.1.3 F値でバランスの良い性能を見る
— 3.1.4 混同行列を知る
— 3.1.5 多クラス分類の平均のとり方: マイクロ平均、マクロ平均
— 3.1.6 分類モデルを比較する
- 3.2 回帰の評価
— 3.2.1 平均二乗誤差
— 3.2.2 決定係数
- 3.3 機械学習を組み込んだシステムのA/Bテスト
- 3.4 この章のまとめ
**4章 システムに機械学習を組み込む
**- 4.1 システムに機械学習を含める流れ
- 4.2 システム設計
— 4.2.1 混乱しやすい「バッチ処理」と「バッチ学習」
— 4.2.2 バッチ処理で学習+予測結果をWebアプリケーションで直接算出する(リアルタイム処理で予測)
— 4.2.3 バッチ処理で学習+予測結果をAPI経由で利用する(リアルタイム処理で予測)
— 4.2.4 バッチ処理で学習+予測結果をDB経由で利用する(バッチ処理で予測)
— 4.2.5 リアルタイム処理で学習をする
— 4.2.6 各パターンのまとめ
- 4.3 ログ設計
— 4.3.1 特徴量や教師データに使いうる情報
— 4.3.2 ログを保持する場所
— 4.3.3 ログを設計する上での注意点
- 4.4 この章のまとめ
**5章 学習のためのリソースを収集しよう
**- 5.1 学習のためのリソースの取得方法
- 5.2 公開されたデータセットやモデルを活用する
- 5.3 開発者自身が教師データを作る
- 5.4 同僚や友人などにデータ入力してもらう
- 5.5 クラウドソーシングを活用する
- 5.6 サービスに組み込み、ユーザに入力してもらう
- 5.7 この章のまとめ
**6章 効果検証
**- 6.1 効果検証の概要
— 6.1.1 効果検証までの道程
— 6.1.2 オフラインで検証しにくいポイント
- 6.2 仮説検定の枠組み
— 6.2.1 コインは歪んでいるか
— 6.2.2 二群の母比率の差の検定
— 6.2.3 偽陽性と偽陰性
- 6.3 仮説検定の注意点
— 6.3.1 繰り返し検定をしてしまう
— 6.3.2 有意差とビジネスインパクト
— 6.3.3 複数の検定を同時に行う
- 6.4 因果効果の推定
— 6.4.1 ルービンの因果モデル
— 6.4.2 セレクションバイアス
— 6.4.3 ランダム化比較試験
— 6.4.4 過去との比較は難しい
- 6.5 A/Bテスト
— 6.5.1 2群の抽出と標本サイズ
— 6.5.2 A/Aテストによる均質さの確認
— 6.5.3 A/Bテストの仕組み作り
— 6.5.4 テストの終了
- 6.6 この章のまとめ
第II部
**7章 映画の推薦システムをつくる
**- 7.1 シナリオ
— 7.1.1 推薦システムとは
— 7.1.2 応用シーン
- 7.2 推薦システムをもっと知ろう
— 7.2.1 データの設計と取得
— 7.2.2 明示的データと暗黙的データ
— 7.2.3 推薦システムのアルゴリズム
— 7.2.4 ユーザー間型協調フィルタリング
— 7.2.5 アイテム間型協調フィルタリング
— 7.2.6 モデルベース協調フィルタリング
— 7.2.7 内容ベースフィルタリング
— 7.2.8 協調フィルタリングと内容ベースフィルタリングの得手・不得手
— 7.2.9 評価尺度
- 7.3 MovieLensのデータの傾向を見る
- 7.4 推薦システムの実装
— 7.4.1 Factorization Machineを使った推薦
— 7.4.2 いよいよFactorizatoin Machineで学習する
— 7.4.3 ユーザーと映画以外のコンテキストも加える
- 7.5 この章のまとめ
**8章 Kickstarterの分析、機械学習を使わないという選択肢
**- 8.1 KickstarterのAPIを調査する
- 8.2 Kickstarterのクローラを作成する
- 8.3 JSONデータをCSVに変換する
- 8.4 Excelで軽く眺めてみる
- 8.5 ピボットテーブルでいろいろと眺めてみる
- 8.6 達成したのにキャンセルされたプロジェクトを見てみる
- 8.7 国別に見てみる
- 8.8 レポートを作る
- 8.9 今後行いたいこと
- 8.10 おわりに
**9章 Uplift Modelingによるマーケティング資源の効率化
**- 9.1 Uplift Modelingの四象限のセグメント
- 9.2 A/Bテストの拡張を通じたUplift Modelingの概要
- 9.3 Uplift Modelingのためのデータセット生成
- 9.4 2つの予測モデルを利用したUplift Modeling
- 9.5 Uplift Modellingの評価方法、AUUC
- 9.6 実践的な問題での活用
- 9.7 Uplift Modelingを本番投入するには
- 9.8 この章のまとめ
参考文献
あとがき
Aki Ariga
Principal Software Engineer
Interested in Machine Learning, ML Ops, and Data driven business. If you like my blog post, I’m glad if you can buy me a tea 😉